Attention Residuals: When Residuals Start Attending To Themselves
Link to paper: Attention Residuals
My previous blog on Manifold Constrained Hyper Connections (mHC) covered how residual connections deserve as much architectural care as attention itself: once you stop treating the residual stream as a fixed identity mapping and instead parameterize it as a learnable routing operator, you recover representational capacity that flat additive skips leave on the table. Building on that perspective, Kimi’s new Attention Residuals paper can be read as another step in the same direction: instead of rigid, hard coded skip paths, residuals become dynamic, learned routing over depth, letting each layer decide which earlier computations it actually wants to carry forward.
From skip connections to depth-wise residual attention
In the “vanilla” Transformer that mHC reacts against, residual connections are intentionally simple. Each block takes a single incoming residual stream, runs its sublayers (attention, MLP), and then just adds the result back on top. The skip has no notion of where information came from or what it represents; it simply adds every prior layer’s output together, with no way to be selective. This is exactly the rigidity that motivated hyper connections: if the backbone of the model is a single additive highway, we are severely limiting how information can flow and be reused across depth.
The core insight draws an analogy between residual connections and RNNs: just as RNNs compress all prior sequence information into a single hidden state, standard residuals compress all prior layer outputs into a single accumulated state. The Transformer solved the RNN bottleneck by replacing recurrence with attention over sequence positions. Attention Residuals apply the same fix to depth: instead of receiving one compressed aggregate, each layer computes a softmax-weighted combination over all prior layer outputs.
The paper introduces two variants:
- Full AttnRes: Unrestricted softmax attention over every prior layer output (highest expressivity, memory scales as O(Ld)).
- Block AttnRes: A two-level scheme that compresses layer history into N block summaries before attending, reducing memory to O(Nd).
Full AttnRes: Softmax attention across all layers
Instead of blindly summing every prior layer’s output, Full AttnRes lets each layer learn which earlier computations actually matter and blends them accordingly. Each layer has a small learned vector, fixed after training, that determines how much weight to give each earlier layer’s output when forming its input. In standard training this is nearly free: those activations are already cached for backprop. The cost only appears at scale, where pipeline parallelism requires transmitting every layer’s output across stage boundaries.
Block AttnRes: Two-level compression for practical scale
Block AttnRes works in two levels.
Within each block, layers are composed exactly as in the standard Transformer, with the usual self-attention and MLP sublayers, and residuals accumulated locally via ordinary addition. Once a block is complete, its accumulated residual state is treated as a single block-level representation. At every layer, an additional cross-block step lets the layer attend over the N previously completed block representations (plus its own current partial state). In this way, the expensive “attend over all past layers” is replaced by “attend over N block checkpoints,” with N ≈ 8 recovering most of Full AttnRes’s gains in practice.
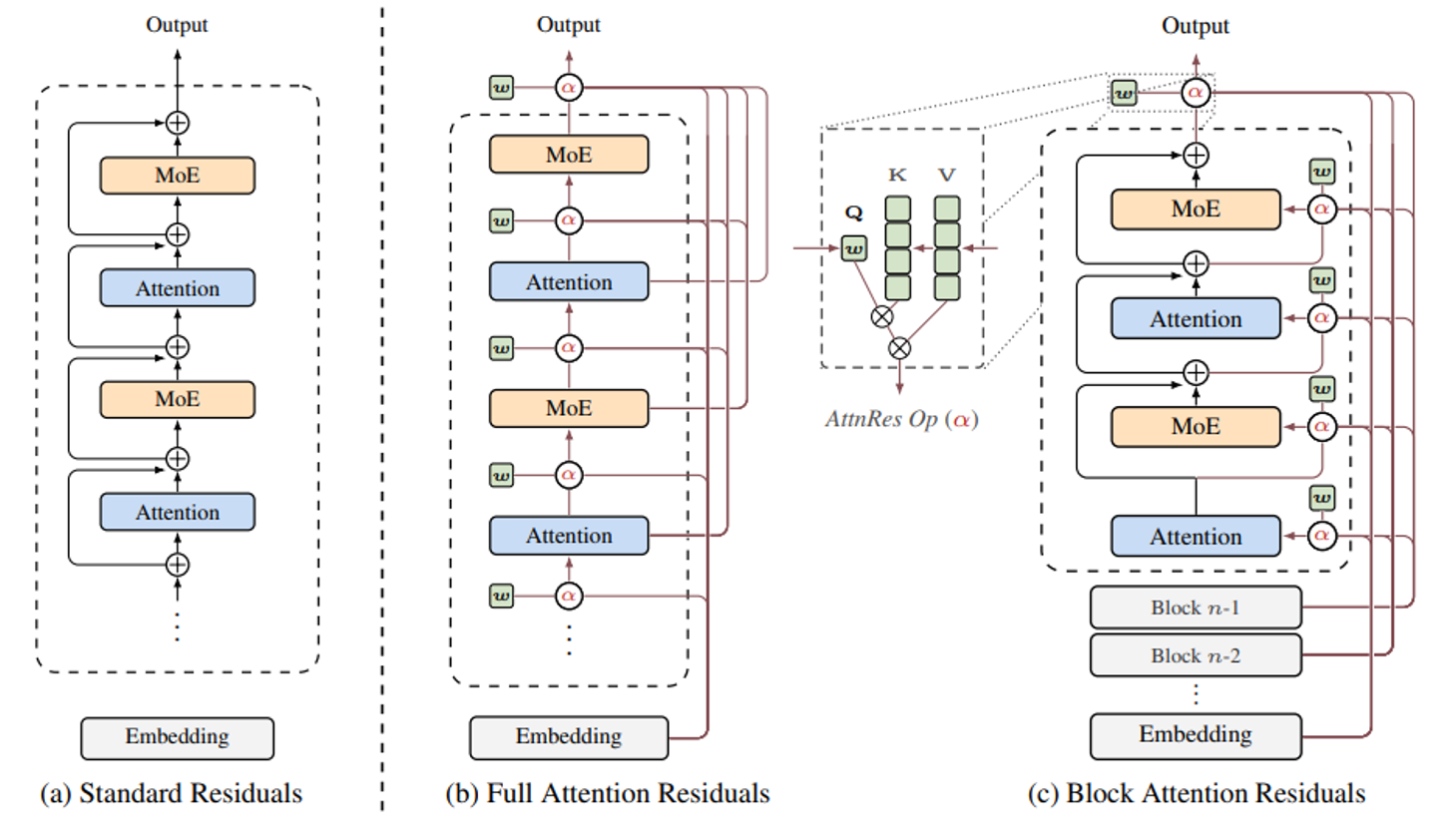 Overview of Attention Residuals. (a) Standard Residuals: standard residual connections with uniform additive accumulation. (b) Full AttnRes: each layer selectively aggregates all previous layer outputs via learned attention weights. (c) Block AttnRes: layers are grouped into blocks
Overview of Attention Residuals. (a) Standard Residuals: standard residual connections with uniform additive accumulation. (b) Full AttnRes: each layer selectively aggregates all previous layer outputs via learned attention weights. (c) Block AttnRes: layers are grouped into blocks
Key results
The Kimi team tested AttnRes on the Kimi Linear architecture (48B total / 3B activated parameters) pre-trained on 1.4T tokens. Both variants beat standard residuals on all evaluated downstream tasks, with Full AttnRes showing stronger gains. Block AttnRes matches the loss of a standard baseline trained with ~1.25× more compute, meaning you get the same model quality for less training budget.
On overhead, the numbers are reassuringly small. Inference latency increases by less than 2%. Training overhead is negligible without pipeline parallelism and less than 4% with it enabled, thanks to cross-stage caching that avoids retransmitting the full block history at every stage boundary.
How this rhymes with mHC
In the mHC post, I focused on DeepSeek’s observation that the classic residual connection is starting to show its limits in deep networks. Hyper Connections generalize residuals into multiple streams with learnable mixing, and mHC further constrains these mixing matrices to live on a stable manifold (e.g., doubly stochastic matrices) to maintain stable gradient flow through depth.
Attention Residuals chase a very similar goal - more expressive and controllable residual routing - but along a different axis. Where mHC adds structure across streams at the same depth, Attention Residuals add structure across layers at different depths. mHC asks: “Given several parallel residual channels right here, how should we mix them while staying stable?” Attention Residuals ask: “Given the entire history of what earlier layers have computed, which of those should this layer actually condition on?” Both are reactions to the same underlying dissatisfaction with flat, additive skips.
Both approaches replace the simple fixed skip connection with a learned routing mechanism: mHC learns how to mix information across parallel streams, Attention Residuals learn which earlier layers to draw from across depth. In both cases, the residual path becomes a deliberate design choice rather than a default.
Placing mHC and Attention Residuals side by side, a clear pattern emerges: residual design is quietly becoming one of the more active frontiers in architecture research. DeepSeek and the MoonshotAI are approaching the same underlying problem from different directions: one targeting geometric stability across streams, the other enabling selective retrieval across depth, and both are arriving at the same conclusion: the flat additive skip is too restrictive for modern deep networks. Whether these two lines of work eventually converge into a unified residual framework is an open question. But the broader momentum is hard to miss. As the field begins treating residual pathways with the same intentionality as attention heads, the designs we settle on in the next few years may look very different from the simple identity-plus-update that has quietly anchored transformer architecture since the beginning.