Manifold-Constrained Hyper-Connections - Rethinking Residual Connections
Link to the original paper: mHC: Manifold-Constrained Hyper-Connections
New year, new paper. DeepSeek kicks off 2026 with a bold challenge to the foundations of deep learning. Just as Kimi’s MuonClip optimizer challenged AdamW in optimization, DeepSeek’s latest work on Manifold-Constrained Hyper-Connections (mHC) questions the status quo established by ResNet’s residual connections. For nearly a decade, skip connections have been the backbone of stable deep networks, but their simplicity has also limited how much information can be shared and reused across layers.
Why revisit skip connections now? Because as models grow deeper and more complex, the fundamental challenge of training them - how gradients propagate through many layers - remains as relevant as ever. The notorious vanishing and exploding gradient problem isn’t just a historical footnote, it’s the reason why innovations like residual connections were needed in the first place, and why researchers continue to seek more expressive yet stable architectures.
To understand the significance of mHC, let’s start at the root of the problem: why training deep neural networks is so difficult, and how the gradient problem shaped the evolution of modern architectures.
The Gradient Problem: Why Deep Networks Struggle
Deep learning relies on backpropagation to update weights layer by layer. As networks grow deeper, gradients - the signals that guide weight updates - tend to either shrink to near zero or grow uncontrollably large. This phenomenon, known as the vanishing and exploding gradient problem, has haunted deep learning since its early days.
Vanishing gradients occur because backpropagation multiplies each layer’s derivative with the one before it. When activation functions like sigmoid or tanh produce derivatives smaller than 1, the repeated multiplication causes the gradient to decay exponentially as it moves toward earlier layers. With almost no learning signal reaching them, those layers train extremely slowly or stop training entirely, preventing the model from converging effectively.
Exploding gradients happen in the reverse situation: when derivatives are consistently greater than 1. As they propagate backward through many layers, the multiplied values grow rapidly, destabilizing training. The network may fail to optimize, with weights oscillating erratically or diverging altogether.
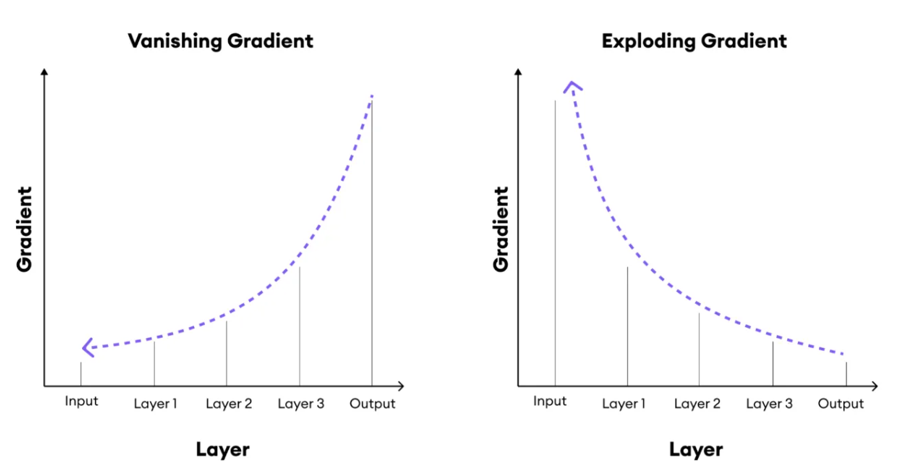 Illustration of the gradient problem: gradients shrink across layers in vanishing gradient (left) and grow uncontrollably in exploding gradient (right), making deep network training unstable.
Illustration of the gradient problem: gradients shrink across layers in vanishing gradient (left) and grow uncontrollably in exploding gradient (right), making deep network training unstable.
To stabilize training, several techniques were introduced. Careful weight initialization schemes like Xavier and He initialization ensure that activations and gradients remain within a reasonable range instead of collapsing or exploding. Activation functions such as ReLU replaced sigmoid and tanh because they preserve stronger gradients. Batch normalization further improved stability by keeping layer inputs well-scaled and speeding up convergence, while gradient clipping imposed an upper limit on gradient size to prevent divergence.
These methods improved stability, but they didn’t fully solve the challenge of training very deep networks. Gradients still had to pass through dozens, or even hundreds, of transformations, and each step introduced risk. The breakthrough came with residual connections, a simple yet powerful idea that gave gradients a shortcut, making it possible to train networks at unprecedented depth.
Residual Connections: The ResNet Revolution
The key idea behind ResNet is that, rather than forcing each layer to learn a complete transformation, each layer learns only the residual: the small change needed to improve the input. This is achieved through skip connections, also called identity mappings, which pass the original input directly to later layers. Mathematically, the output becomes: $\text{Output} = F(x) + x$.
Here, $x$ is the original input, and $F(x)$ is the transformation applied by the residual block. By adding them together, the network ensures that the original signal flows through unchanged while the layer focuses on refining it. If the best option is “do nothing,” the network can simply learn $F(x)=0$, making optimization far easier than approximating an identity function, which would require it to replicate the input exactly.
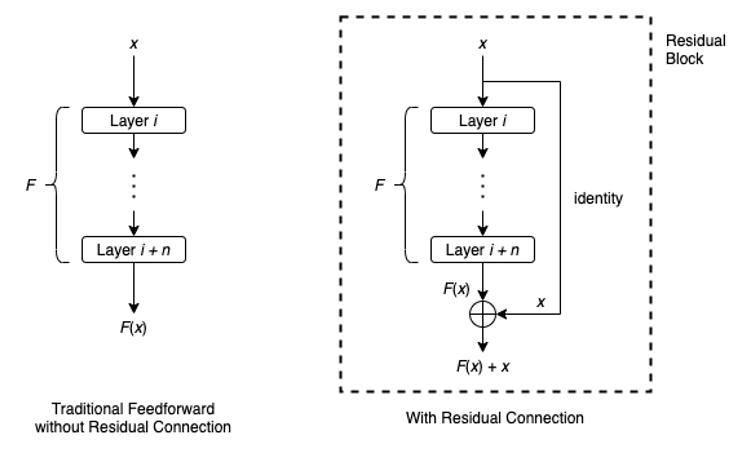 Comparison of traditional feedforward blocks and residual blocks: ResNet adds a skip connection (identity mapping) so the output becomes $F(x)+x$, enabling better gradient flow and easier optimization.
Comparison of traditional feedforward blocks and residual blocks: ResNet adds a skip connection (identity mapping) so the output becomes $F(x)+x$, enabling better gradient flow and easier optimization.
This design solves the vanishing gradient problem by creating direct paths for gradients to flow backward, allowing early layers to keep receiving strong learning signals even in very deep networks. Because each layer includes an explicit identity mapping, gradients can bypass poorly conditioned transformations and reach earlier layers without being repeatedly attenuated. It also smooths the optimization landscape, making training more stable. Residual connections became the backbone of architectures like ResNet and later influenced models such as Transformers, where they are applied around attention and feed-forward layers.
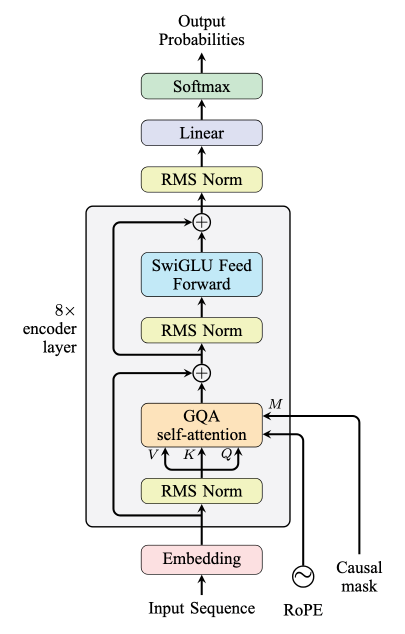 Decoder-only Transformer architecture: attention and feed-forward layers wrapped in residual blocks with RMSNorm for stable training and smooth gradient flow.
Decoder-only Transformer architecture: attention and feed-forward layers wrapped in residual blocks with RMSNorm for stable training and smooth gradient flow.
Standard residual connections follow a simple local pattern: each block computes a transformation $F(x)$ and adds it to the input $x$. In the basic formulation, the skip path remains a fixed identity operation, meaning the input’s contribution is uniformly weighted with no learnable mechanism to gate or rebalance new versus old information. Moreover, residual connections provide a single, local information pathway that only mixes adjacent layers, limiting how flexibly information can be redistributed across depth. This architectural limitation motivates richer designs such as Hyper-Connections and Manifold-Constrained Hyper-Connections (mHC), which introduce multiple interaction pathways while addressing stability concerns.
Hyper-Connections: From Rigidity to Richness
Introduced by ByteDance in 2024, Hyper-Connections extend the residual concept into a dynamic, multi-stream architecture. Instead of a single shortcut, the network maintains multiple parallel residual streams, allowing each layer to read from all streams, mix information, and write back adaptively.
The breakthrough lies in learnable depth and width connections. Depth connections link layers vertically across the network’s depth. Instead of a fixed identity mapping, each layer learns how strongly to connect to previous layers through weighted combinations.
Width connections operate horizontally across parallel streams at the same depth. For example, when a model has multiple residual branches processing information in parallel, width connections allow these branches to exchange information. This means one stream can learn to attend to features discovered by another, creating richer representations than isolated pathways.
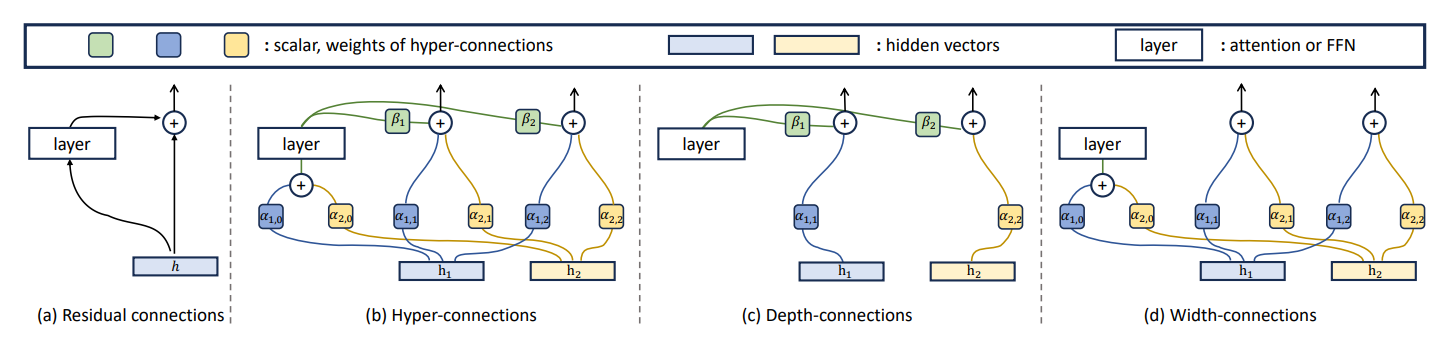 Evolution from Residual Connections to Hyper-Connections
Evolution from Residual Connections to Hyper-Connections
(a) Residual Connections: The classic design uses a single skip path that adds the previous hidden state h to the layer output with a fixed weight of 1. This identity mapping ensures stability but limits flexibility.
(b) Hyper-Connections: Instead of one shortcut, the network maintains multiple parallel residual streams. Each layer can read from all streams, mix information, and write back dynamically. Trainable scalars (α and β) control the strength of these connections, replacing the rigid identity mapping with adaptive pathways.
(c) Depth Connections: These learnable weights govern vertical information flow across layers. Scalars α determine how much influence earlier hidden states (e.g., h_1,h_2) have on the current layer’s computation, while β controls how strongly the current layer writes back into the residual stream for future layers.
(d) Width Connections: These operate horizontally across parallel streams within the same layer. Scalars α define how much one hidden representation contributes to another, enabling lateral mixing. This mechanism creates multiple interacting views of the input, increasing representational flexibility compared to isolated pathways.
This expressivity, however, comes at a cost. By breaking the strict identity property of residuals, Hyper-Connections introduce instability. Information is repeatedly mixed across streams, and as layers stack, these mixing operations compound. Small imbalances grow exponentially, causing signals to become either too strong or too weak. In large-scale models, this led to catastrophic amplification: signals exploding by up to 3000x in a 27B-parameter network, making training fail without additional constraints.
This instability highlighted a critical need for structural guardrails, a way to keep the flexibility of Hyper-Connections without letting signals spiral out of control, setting the stage for the next breakthrough.
Manifold-Constrained Hyper-Connections: Guardrails for Stability
mHC introduces a simple but powerful principle: when information is mixed, the operation is structured so that the overall signal strength remains well controlled. It can be flexibly redistributed across streams, but not allowed to grow without bound or vanish. To enforce this, mHC projects residual connections onto a manifold and applies normalization during training. The mixing weights are learned within this constrained space, keeping interactions between streams stable while still enabling routing of information between layers, effectively restoring the stable identity-like behavior that Hyper-Connections disrupted.
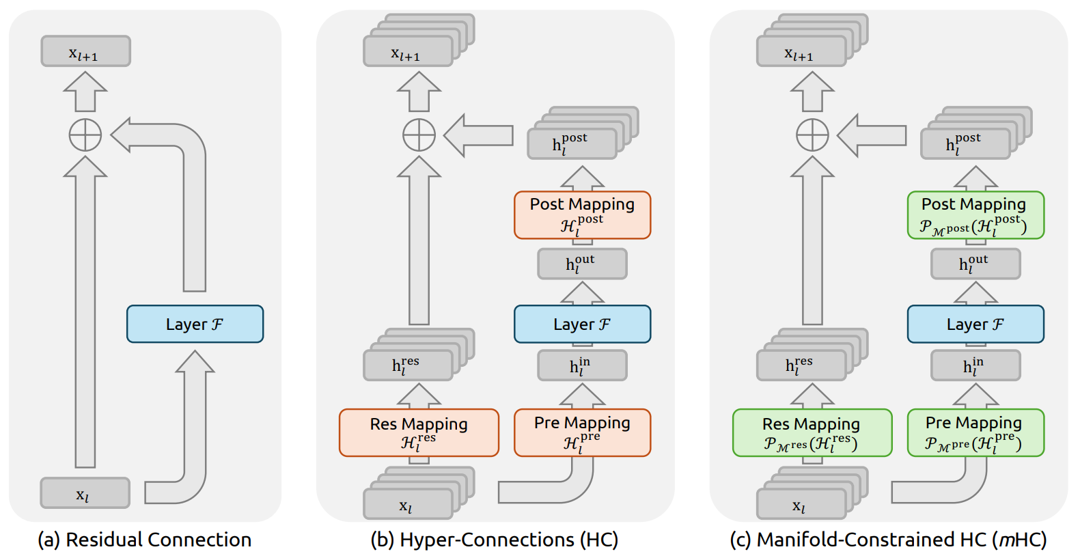 Evolution of Skip Connection Designs from Residuals to mHC
Evolution of Skip Connection Designs from Residuals to mHC
(a) Residual connections preserve stability through a fixed identity pathway that guarantees unattenuated gradient flow.
(b) Hyper Connections (HC) extend this design by introducing learnable pre, post, and residual mappings that flexibly mix information across residual streams, increasing expressivity but removing structural guarantees on stable signal propagation.
(c) Manifold Constrained Hyper Connections (mHC) restore stability by projecting these mixed representations onto a constrained manifold, ensuring information is redistributed rather than amplified and maintaining stable forward and backward signal flow.
The manifold constraints translate directly into training stability. By ensuring information is redistributed rather than amplified at each layer, mHC prevents the cascading signal explosions that plagued unconstrained Hyper-Connections. The evidence is striking: maximum gradient amplification dropped from 3000x (HC) to 1.6x (mHC), a three-order-of-magnitude improvement that means the difference between divergent training runs and smooth convergence, all achieved with only a 6.7% training overhead.
DeepSeek tested mHC against baseline architectures and unconstrained Hyper-Connections across 3B, 9B, and 27B models, all built on DeepSeek-V3 MoE architecture with Multi-Head Latent Attention. For both HC and mHC, the expansion rate was set to 4 residual streams. The table below shows results for the 27B model:
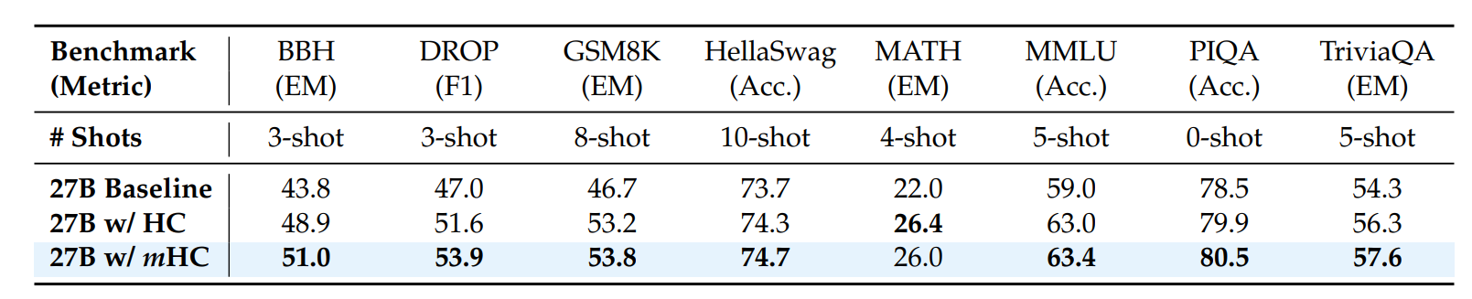
mHC delivers broad improvements, consistently outperforming the baseline and surpassing HC across most tasks. In particular, it strengthens reasoning capabilities, achieving gains of +2.1% on BBH and +2.3% on DROP compared to HC.
To understand why mHC outperforms HC, we next examine the learning dynamics and signal propagation during training.
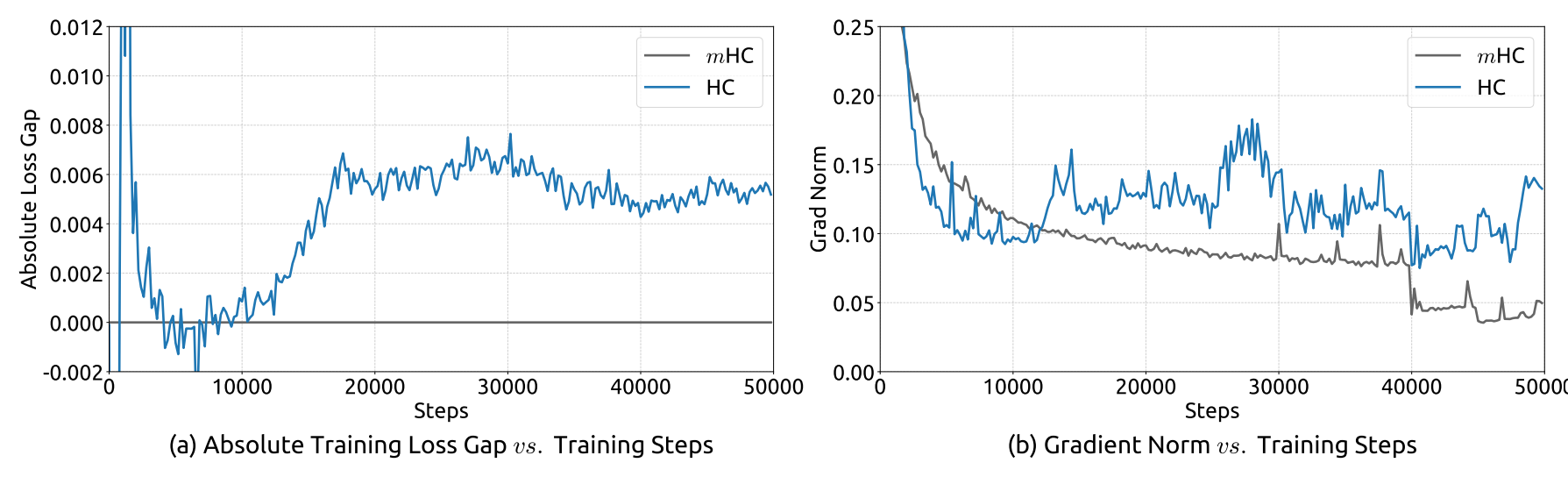
The top two graphs compare loss gap and gradient norms during training for HC and mHC on a 27B model.
- (a) Loss Gap: mHC serves as the baseline. HC consistently shows a higher loss than mHC, indicating worse predictions. Note the surge in loss in HC around 12K steps, which is correlated with the instability in the gradient norm.
- (b) Gradient Norms: mHC stabilizes quickly and remains smooth throughout training, reflecting controlled and consistent weight updates. In contrast, HC exhibits jagged, oscillating patterns, which are signs of erratic and unstable training behavior.
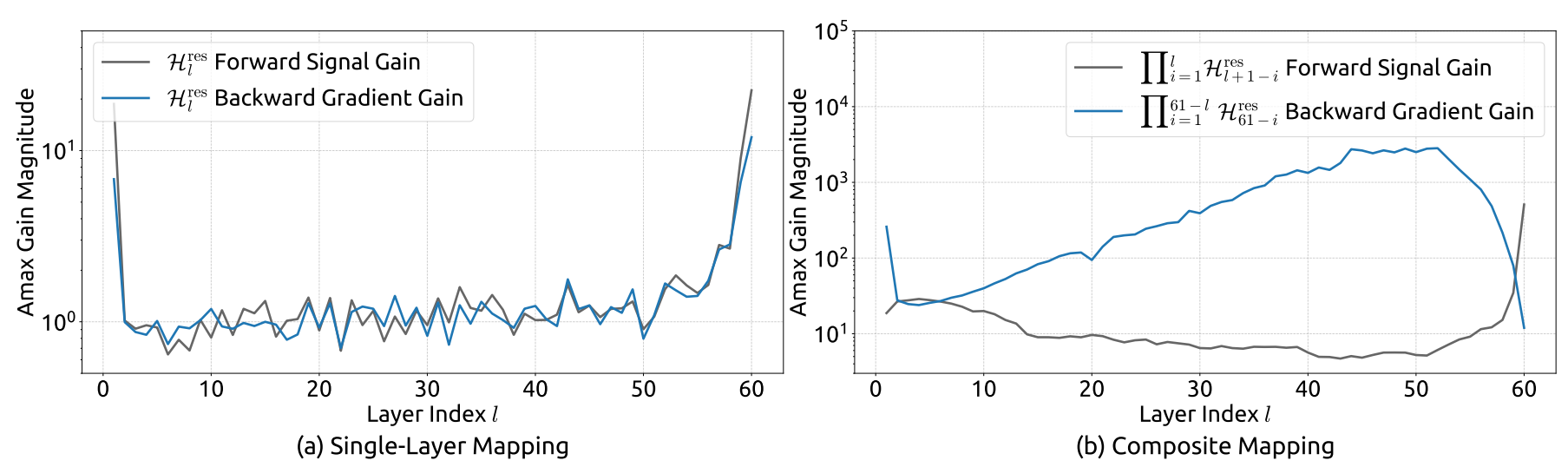

The above four graphs illustrate signal amplification (gain) across layers:
- For HC (top graphs), cumulative gain spikes dramatically, reaching up to 3000x amplification as layers stack. This exponential growth leads to exploding gradients and instability.
- For mHC (bottom graphs), gains remain tightly bounded, with cumulative amplification well below 2x. No spikes, no runaway gradients - mHC enforces stability by keeping signal propagation balanced across depth
These analyses demonstrate that mHC not only stabilizes training by controlling gradient and signal flow, but also translates this stability into tangible performance improvements, achieving consistent gains over HC across benchmark tasks such as BBH (+2.1%) and DROP (+2.3%).
Rethinking the foundations
The evolution of deep learning shows that progress often comes from questioning assumptions. We made networks deeper to improve performance, only to encounter instability that limited training. Skip connections addressed this problem, but their fixed structure still imposes constraints that shape how information flows through the network.
mHC demonstrates that revisiting these design choices can yield substantial gains. By constraining signal mixing and bounding amplification, mHC stabilizes training and enables more reliable gradient flow, without reducing the network’s capacity to learn complex representations. The reduction from extreme amplification (3000x) to a controlled range (≈1.6x) highlights how careful mathematical design can directly improve both stability and performance.
Looking ahead, these results show that even well-established architectural principles can be refined. Approaches like mHC illustrate that thoughtful adjustments to core network design can further improve training stability and performance, particularly as models continue to scale.