Introduction to Mixture-of-Experts
In recent years, the original Transformer architecture has undergone significant enhancements to improve efficiency, scalability, and overall performance.
One of these innovations include the adoption of Mixture-of-Experts (MoE) models. Unlike traditional dense Transformers, MoE introduces sparsity by activating only a subset of specialized expert layers for each input, reducing computational overhead while maintaining or even improving model quality. This shift enables larger models to be trained and deployed more cost-effectively, paving the way for faster and more resource-friendly architectures.
Alongside MoE, several other advancements have transformed the way modern Transformers operate. The attention mechanism, which lies at the heart of the architecture, has evolved from the original multi-head design to more efficient variants such as multi-query, grouped-query attention and even more recent multi-head latent attention, reducing memory footprint and improving inference speed. Computation itself has been optimized through techniques like Flash Attention and Paged Attention, which significantly reduce memory overhead and accelerate training by rethinking how attention kernels are computed and stored. Recently, we’ve seen a surge in hybrid attention mechanisms that combine the strong performance of full (quadratic) attention with the efficiency of linear attention. A notable example is Qwen3-Next, an 80B-parameter MoE model with only 3B active parameters during inference. It blends Gated DeltaNet with standard gated attention in a 3:1 ratio, achieving both scalability and expressivity. Building on this, Kimi-Linear introduces Kimi Delta Attention - a refined evolution of Gated DeltaNet - and pairs it with multi-head latent attention, also at a 3:1 ratio.
Positional encoding has also seen improvements: the traditional sinusoidal approach has largely been replaced by Rotary Position Embeddings (RoPE), which better preserve relative positions and enable models to scale to longer sequences without performance degradation.
Other refinements include changes to activation functions and normalization strategies. The simple ReLU has given way to smoother and more expressive functions like GELU, and later SwiGLU and SiLU, improving gradient flow and overall model expressiveness. Similarly, normalization has evolved from LayerNorm to RMSNorm, a lighter alternative that stabilizes training and reduces computational cost.
Together, these innovations - spanning attention mechanisms, computational optimizations, positional encoding, activation functions, and normalization - represent a major leap forward from the original Transformer design. They enable models to process longer contexts, train more efficiently, and deliver higher performance, all while keeping resource requirements in check.
Mixture-of-Experts
Having outlined the broader architectural improvements, let’s now dive deeper into the first innovation mentioned earlier: Mixture-of-Experts (MoE) models. MoE represents a fundamental shift from the dense Transformer paradigm toward a more efficient, sparse architecture. Instead of activating every layer for every input, MoE selectively routes tokens through a small subset of specialized “expert” layers. This means that during inference only a small fraction of the model’s parameters are active. As a result, computational overhead is drastically reduced while preserving - and often improving - model quality.
At the architectural level, the dense feed-forward network (FFN) layers found in traditional Transformers are replaced by MoE layers. These layers consist of multiple experts, each being a feed-forward subnetwork, and a gating mechanism that determines which experts should process a given token. By activating only a few experts per input rather than all of them, MoE introduces conditional computation, enabling models to scale to billions or even trillions of parameters without a proportional increase in compute cost. This design makes it possible to train and deploy extremely large models while keeping resource requirements manageable.
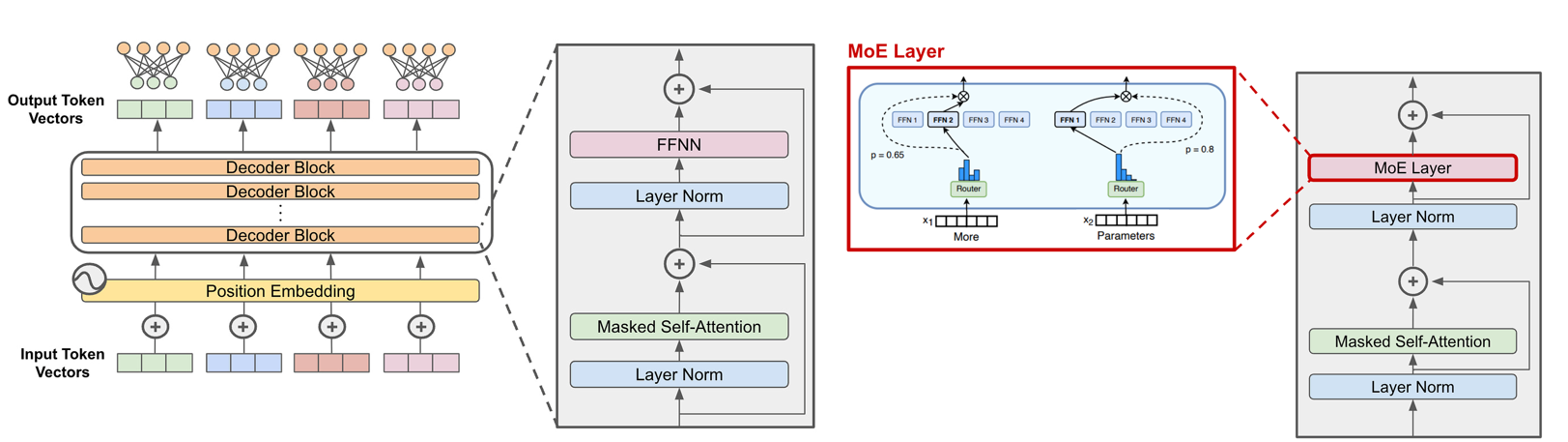 Comparison of traditional Transformer architecture with dense FFN layers versus Mixture-of-Experts (MoE) architecture, where FFN layers are replaced by sparse MoE layers using expert routing.
Comparison of traditional Transformer architecture with dense FFN layers versus Mixture-of-Experts (MoE) architecture, where FFN layers are replaced by sparse MoE layers using expert routing.
A key advantage of MoE is that each expert can specialize in certain token patterns, linguistic structures, or domain-specific knowledge. This specialization allows the model to capture diverse knowledge without redundancy and improves overall efficiency. An additional architectural enhancement is the shared expert, which is always activated alongside the selected sparse experts. This shared expert captures common knowledge across tasks, reducing duplication and allowing routed experts to focus on more specialized, non-overlapping areas. For example, Qwen3-Next follows this approach, combining ten routed experts and one shared expert.
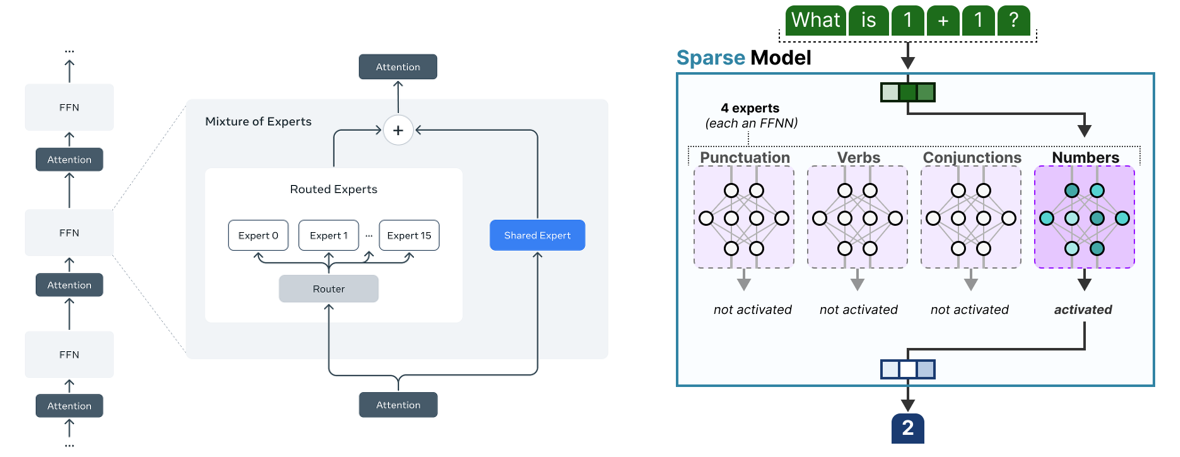 Left: MoE architecture with 16 routed experts and one shared expert. Right: Experts specializing in linguistic concepts
Left: MoE architecture with 16 routed experts and one shared expert. Right: Experts specializing in linguistic concepts
While MoE brings significant benefits, it also introduces trade-offs. On the positive side, inference is faster compared to a dense model with the same total number of parameters, and the model is more powerful than one with the same number of active parameters because of its conditional computation. However, routing introduces a slight overhead, making MoE marginally slower than an equivalent dense model in some cases. On the downside, MoE requires high VRAM because all experts must be loaded into memory even if only a few are active at a time. Balancing the load among experts is challenging, as the routing mechanism can converge toward favoring a small subset of experts, leading to underutilization of others. Finally, training can be unstable without careful tuning of routing strategies and capacity constraints.
Expert routing
A critical component of Mixture-of-Experts architectures is the routing mechanism, which determines which experts process each token during training and inference. This routing is handled by a lightweight gating network, typically a feed-forward layer followed by a SoftMax, that outputs probabilities for each expert. Based on these probabilities, the model selects the top experts for each token. Importantly, the router and the experts are jointly trained, ensuring that both the gating decisions and expert parameters evolve together during optimization.
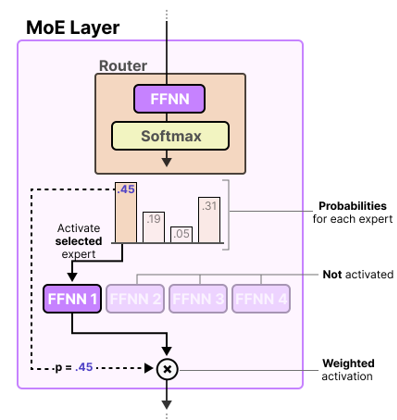 Illustration of a Mixture-of-Experts (MoE) layer showing the routing process. A lightweight gating network (FFNN + Softmax) computes probabilities for each expert. The top expert is selected and activated based on its probability score (e.g., 0.45), while others remain inactive. The selected expert processes the token, and its output is weighted by the activation probability before passing to the next layer.
Illustration of a Mixture-of-Experts (MoE) layer showing the routing process. A lightweight gating network (FFNN + Softmax) computes probabilities for each expert. The top expert is selected and activated based on its probability score (e.g., 0.45), while others remain inactive. The selected expert processes the token, and its output is weighted by the activation probability before passing to the next layer.
However, routing introduces several challenges. Without constraints, the router often converges to favoring a small subset of experts, leading to routing imbalance. This results in undertrained experts and underutilized capacity: experts are loaded into memory but provide little value if they are rarely selected, consuming resources without contributing effectively. In addition, when experts are distributed across multiple GPUs through expert parallelization, an uneven token distribution can create bottlenecks if certain GPUs receive significantly more tokens than others. To mitigate these issues, techniques like Noisy Top-k gating with Gaussian noise are used to add randomness and prevent the same experts from being repeatedly selected.
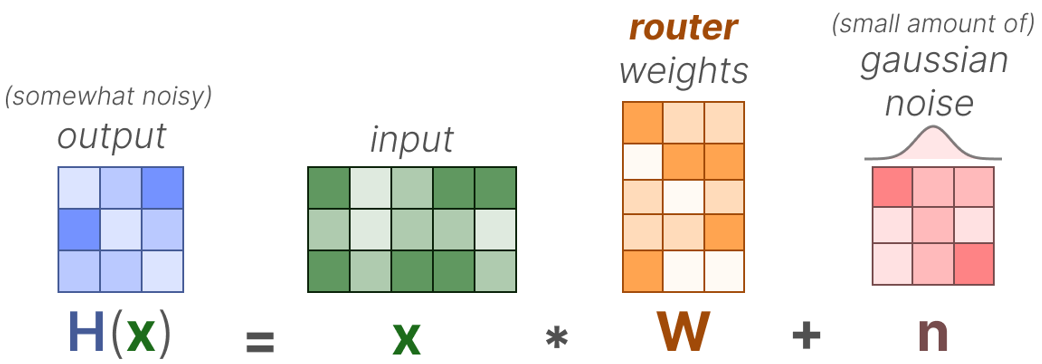 Noisy Top-k gating with Gaussian noise
Noisy Top-k gating with Gaussian noise
Another strategy is the use of an auxiliary loss that encourages balanced expert utilization. This loss sums the probability distributions for each expert across the entire batch and computes a coefficient of variation (CV) to measure how unevenly tokens are distributed. Minimizing the CV score ensures that all experts receive roughly the same number of training examples, improving overall model robustness.
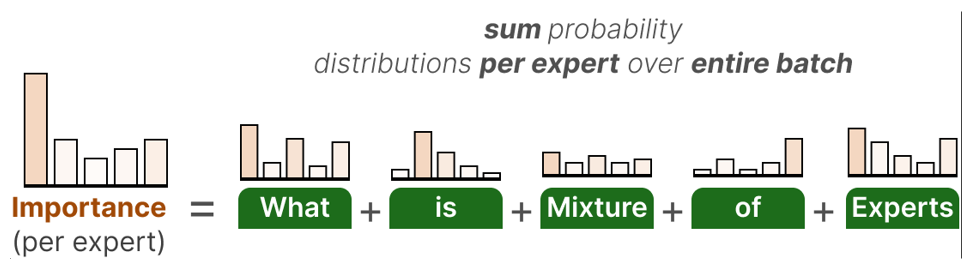
Expert capacity is another consideration. Each expert can only process a limited number of tokens per batch. When capacity is exceeded, overflow tokens may be routed to the next expert, deferred to the next layer, or dropped entirely (which could hurt performance).
An alternative approach called Expert Choice routing flips the paradigm: instead of tokens choosing experts, experts select the tokens they want to process from the entire batch. Each expert examines all tokens in the batch and picks the top candidates within its fixed capacity.
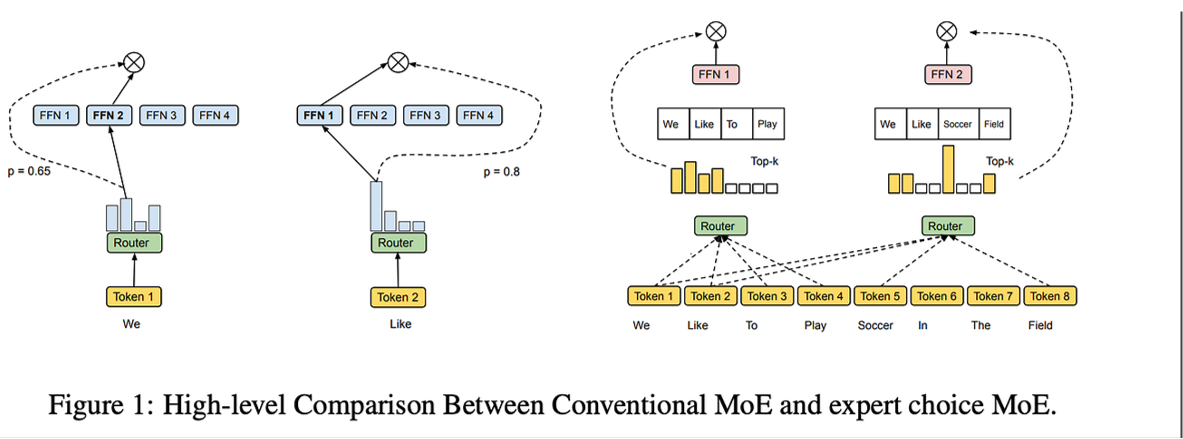
These represent just some of the techniques developed to address routing challenges in MoE architectures. Many other approaches exist, and researchers continue to develop new methods to improve expert utilization, reduce communication overhead, and enhance the efficiency of sparse models.
FrankenMoEs or MoErges
While Mixture-of-Experts models have become a cornerstone of scaling strategies for large language models, researchers and enthusiasts have experimented with more unconventional ideas, one of the more intriguing being FrankenMoEs, or MoErges. Think of this as a creative “upcycling” approach: instead of training experts and routers together from scratch, FrankenMoEs merge existing specialized models that already perform well in different domains and then bolt on a routing mechanism afterward. It’s a bit like stitching together different creatures in a lab: fun, experimental, and not always elegant.
The router in these setups can be trained on a calibration dataset or even replaced with deterministic rules, such as domain classification. However, because the experts were never co-adapted during training, this approach introduces quirks: routing isn’t jointly optimized, switching experts mid-sequence can break coherence, and experts may have different styles or output distributions. To make this work, all merged models must share the same architecture and tokenizer, which limits flexibility. Performance is generally suboptimal compared to fully trained MoEs, but the trade‑off is simplicity: FrankenMoEs are far easier to build because they reuse existing pretrained models instead of requiring the costly, unstable process of training experts and routers jointly from scratch. This makes them a nice playground for experimentation despite their limitations. Besides, who doesn’t secretly want to create their own little Frankenstein monster?
One practical way to build FrankenMoEs is with Mergekit, a Python library designed for model merging. Mergekit provides tools to fuse different models into a single composite, making it possible to route across multiple expert domains. It’s worth noting that this is just one way to combine models - model merging itself is a much broader topic with techniques that go far beyond MoE.
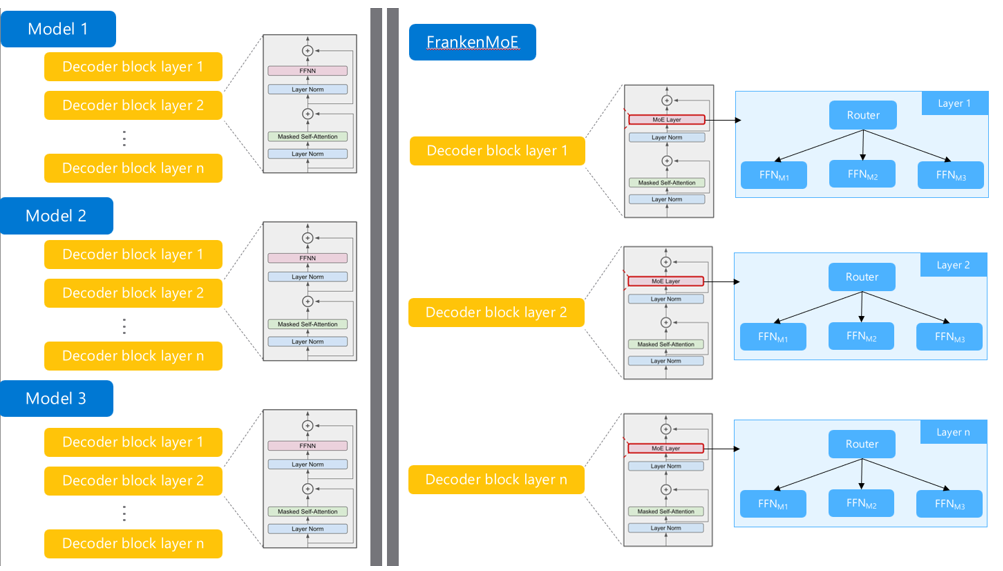 FrankenMoE is created by taking the FFNs from the same layer position across multiple pre-trained models and combining them into a single Mixture-of-Experts layer. For example, all Layer 1 FFNs from Model 1, Model 2, and Model 3 are grouped together as experts in Layer 1 of the FrankenMoE. The same process is repeated for Layer 2, where all Layer 2 FFNs from the three models become experts in Layer 2 of the FrankenMoE, and so on for every subsequent layer.
FrankenMoE is created by taking the FFNs from the same layer position across multiple pre-trained models and combining them into a single Mixture-of-Experts layer. For example, all Layer 1 FFNs from Model 1, Model 2, and Model 3 are grouped together as experts in Layer 1 of the FrankenMoE. The same process is repeated for Layer 2, where all Layer 2 FFNs from the three models become experts in Layer 2 of the FrankenMoE, and so on for every subsequent layer.
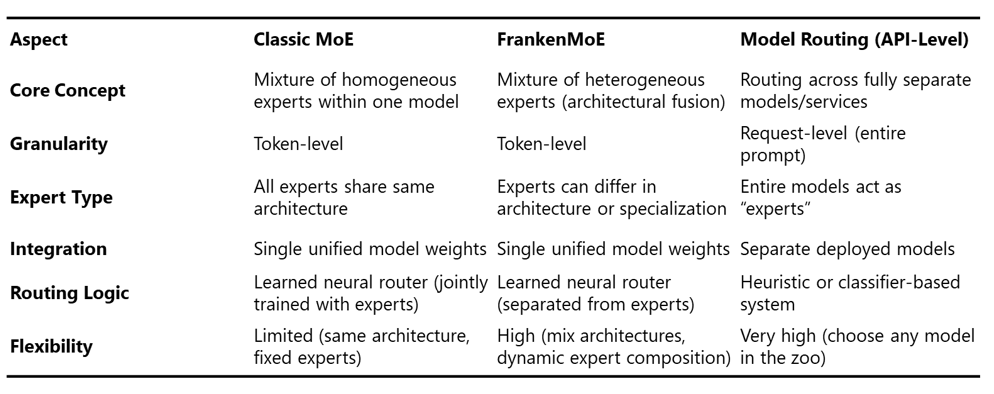
Not a model router
It’s important to note that Mixture-of-Experts is not the same as model routing. MoE operates inside a single model, routing tokens to different experts within its architecture. In contrast, model routing works at a much higher level, directing entire requests across fully separate models or services, treating each model as an “expert.” This difference in granularity and integration leads to very different design trade-offs. The table below summarizes the key distinctions between the traditional MoE, FrankenMoE, and Model Routing.
Mixture-of-Experts architectures represent a fundamental shift in how we approach model scaling. Rather than simply making models denser and more computationally expensive, MoE introduces sparsity as a first-class design principle. By activating only a subset of experts per token, these architectures achieve an appealing balance: the efficiency of smaller models during inference with the capacity of much larger ones. However, as we’ve explored, this efficiency comes with its own set of challenges: from routing imbalances to memory requirements to training instability. The ongoing research into better routing mechanisms, load balancing techniques, and architectural innovations like shared experts shows that MoE remains an active and evolving area. As these challenges are addressed, MoE architectures are likely to become even more prevalent in the next generation of language models.